Remote Procedure Call
Remote Procedure Call (RPC) 使得调用远程函数就像调用本地函数一样,这样就不需要关心资源的具体问题,实际上 RPC 是将方法调用转换成了网络通信。但是遇到通信失败怎么办?
- 如果在函数调用过程中,服务挂了?
- 如果消息丢失了?
- 如果消息延迟了?
- 如果出了问题,回复消息是否安全?
要解决这些问题,就需要将网络以及节点之间的情况抽象出来,以及时序的问题。在设计分布式算法时,需要更加抽象一点,以便更好的推理整个过程。
System model
Network behaviour
The two generals problem 描述了网络通信丢失的场景。
假设两个节点之是间双向的点对点的通信。
Reliable links
一条消息只会在被一个节点发送的时候才会收到,并且消息是可以重新排序的。
中间没有伪造消息等行为,发送了就一定会被收到。
Fair-loss links
消息可能会丢失、重复或重新排序,如果你一直重新发送,消息终将会传递过去。
每次发送消息成功的概率都是非零,这个时候只要一直重试,我们就假设消息一定会传递到另外一个节点。
Fair-lose links 其实可以通过不断的重试以及并且对重复收到的消息去重,就可以达到 Reliable links 的效果。
Arbitrary links
可能传递过程中会有恶意的第三方对消息进行干预。
比如公共场合的公共 WiFi 就会出现这种情况。
Arbitrary links 通过 TLS 的加持,就可以达到 Fair-loss links 的效果。
Nodes behaviour
The Byzantine generals problem 描述了节点出错,导致全体协作策略失败以及容错率的问题。
假设每个节点都执行指定的算法,假设有以下情况。
Crash-stop (fail-stop)
如果一个节点出现问题挂了,并且在这之后永远停机。
Crash-recovery (fail-recovery)
一个节点挂了,并丢失了内存状态,但会在过段时间后恢复。
Byzantine (fail-arbitrary)
节点偏离了原本的算法,可能会发生任何事情,包括崩溃或者恶意的行为。
Synchrony (timing) assumption
Synchronous
消息延迟不超过已知的上限。到达这个上限后,消息要么被传递,要么丢失。节点以已知的速度执行算法。每一步代码的执行都有执行时间的上限。
Partically synchronous
系统中一部分时间内是异步的,另一部分是同步的。
Asynchronous
消息可以任意地被延迟,节点可以任意地暂停,并没有时序上的保证。
Clocks and time in distributed systems
分布式系统中经常涉及到需要测量时间,比如:
- Schedulers, timeouts, failure detectors, retry timers
- Performance measurements, statistics, profiling (performance analysis 也称为 profiling)
- Log files & databases: record when an event occurred
- Data with time-limited validity (e.g. cache entries)
- Determining order of events across several nodes
分布式系统中会遇到两种类型的时钟:
- physical clocks: count number of seconds elapsed
- logical clocks: count events, e.g. messages sent
Clock synchronisation
物理时钟会有时间上的偏移,通常是通过和电脑、手机、电视等相对准确的地方来校准物理时钟的时间,比如手表,老式的钟摆。
电脑上的时间同样会有偏移,是通过 Network Time Protocol(NTP) 来校准电脑的时间,也就是物理时钟的校准。
Broadcast protocols and logical time
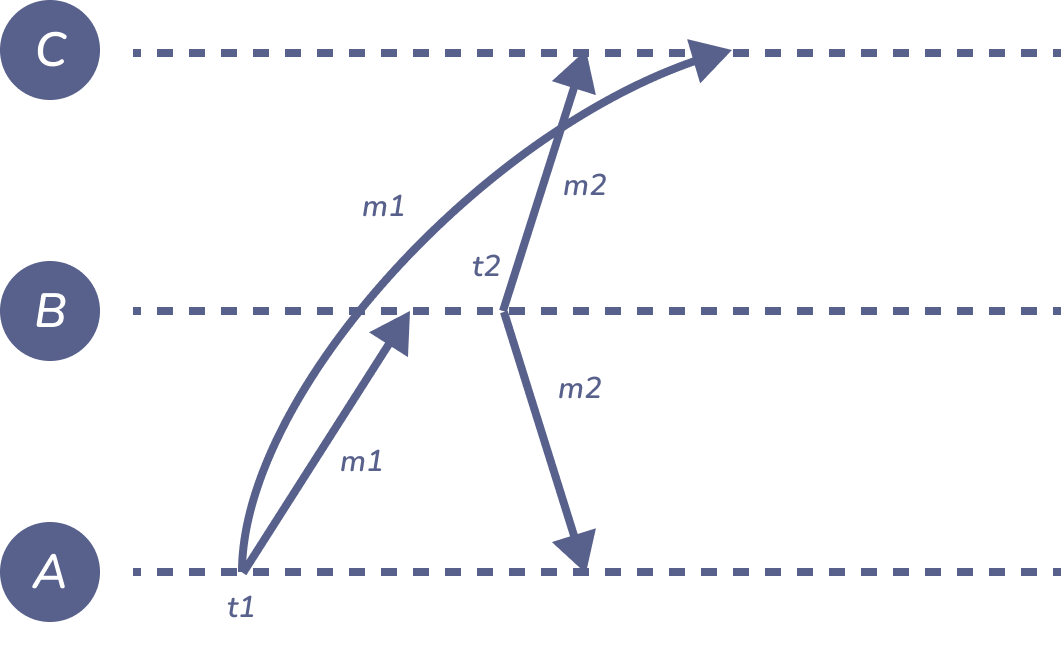
Figure 1: ordering-of-messages
\(m_{1}\) = “A says: The moon is made of cheese!”
\(m_{2}\) = “B says: Oh no it isn’t!”
User C sees \(m_{2}\) first, \(m_{1}\) second, even though logically \(m_{1}\) happened before \(m_{2}\).
Problem: even with synced clocks, \(t_{2 }< t_{1}\) is possible. Timestamp order is inconsistent with expected order!
即便我们已经通过 NTP 尽量保证物理时钟上的同步,但这个时候依旧会发生因果关系不一致的情况,所以这个时候就需要逻辑时钟。
逻辑时钟是在分布式系统中专门用于捕获系统中发生事件之间的因果关系,因此逻辑时钟其实就是一种计数器,每次事件发生的时候都会往前递增,所以随着事件的发生它会随着时间向前移动,但它和物理时间并没有实际的关系。
Logical time
Logical clocks: designed to capture causal dependencies.
\((e_{1} \rightarrow e_{2}) \Longrightarrow (T(e_{1}) < T(e_{2}))\)
当事件1发生在事件2之前,那么事件1的时间戳应该小于事件2的时间戳,这是逻辑时钟要保证的最基本的原则。
下面将研究一下两种逻辑时钟:
-
Lamprot clocks 是在分布式系统中的每个节点都维护一个计数器,每一个当前节点事件 \(e\) 发生时自增 ;发送消息时,也会附带上当前节点的计数 \(t\) ,消息接收者收到消息后,取出消息中的计数器与当前节点计数器比较,去最大值后自增 1。
这样可以实现局部顺序,再加上节点名称,形成(时间戳,节点名称)的组合后,就可以扩展为全局顺序。
但这样也有缺点,算法在时间戳相同,节点名称不同的平行事件的顺序判定时,会出现与实际情况不符的情况。1
-
Vector clocks 除了是向量之外,向量时钟算法与 Lamport 时钟非常相似。一个节点的向量时钟的初始值是系统中的每个节点的事件数,也就是 0。每当节点 \(N_{i}\) 发生事件时,它就会增加其向量钟中的第 \(i\) 个条目(它自己的条目)。(In practice, this vector is often implemented as a map from node IDs to integers rather than an array of integers. 在实践中,这里的向量通常是节点 ID 对应 Integer 的 map,而不是 Integer 的数组。)。当一个消息在网络上被发送时,发送者当前的向量时间戳被附加到该消息上。最后,当一个消息被接收时,接收者将消息中的向量时间戳与它的本地时间戳合并,方法是取两个向量的元素的最大值,然后接收者增加它自己的条目
这样就可以弥补 Lamport 的缺点,可以完全确定每个事件的因果顺序。
Delivery order in broadcast protocols
许多网络提供点对点(单播)的信息传递,其中一个信息有一个特定的收件人。广播协议对网络进行了概括,使一条信息被发送到某个组的所有节点。组的成员可能是固定的,或者系统可能提供节点加入和离开组的机制。
一些局域网在硬件层面提供组播或广播(例如,IP 组播),但互联网上的通信通常只允许单播。此外,硬件级的组播通常是在 best-effort 基础上提供的,允许消息被丢弃;要使其可靠,需要类似于这里讨论的重传协议。
上面提到的 node behaviour 和 synchrony 的系统模型假设直接延伸到广播组。
Broadcast protocols
Broadcast (multicast) is group communication:
- 一个节点发送消息,所有组内节点传递。
- 组内成为可以是固定的也可以是动态的
- 如果一个节点发生错误,剩余的组内成员顶上。
- Note: 这个观念比 IP 组播更加普遍
建立在之前讲到的系统模型上:
- 可以是 best-effort (可能会丢失消息) 或者 reliable (非故障节点传递每条消息,重传丢失的消息。)
- Asynchronous / partially synchronous timing model \(\Longrightarrow\) 消息延迟没有上限
Receiving versus delivering
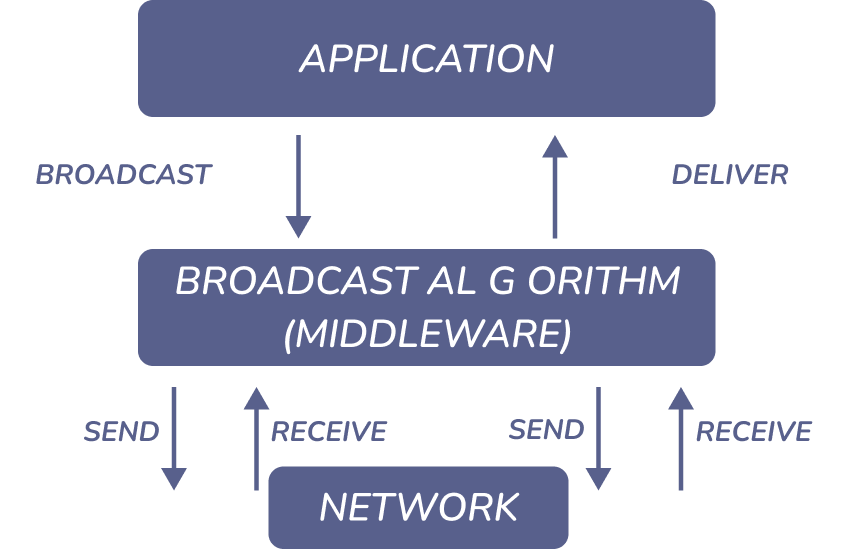
Figure 2: receive-versus-deliver
假定网络提供点对点的发送/接收,在广播算法从网络中收到消息后,传递给应用前会在缓存或者队列当中。
下面将研究三种不同形式的「广播」。所有这些都是可靠的:每条消息最终都会被传递到每个非故障节点,但没有时间上的保证。然而,它们在每个节点上传递信息的顺序方面存在差异。事实证明,这种顺序上的差异对实现广播的算法有非常根本的影响。
Forms of reliable broadcast
-
如果 \(m_{1}\) 和 \(m_{2}\) 从相同的节点广播,并且 broadcast(\(m_{1}\)) \(\longrightarrow\) broadcast(\(m_{2}\)),那么 \(m_{1}\) 必然在 \(m_{2}\) 之前被传递。
-
如果 broadcast(\(m_{1}\)) \(\longrightarrow\) broadcast(\(m_{2}\)) 那么 \(m_{1}\) 必然在 \(m_{2}\) 之前被传递。
-
如果在同一个节点 \(m_{1}\) 在 \(m_{2}\) 之前被传递,那么所有节点 \(m_{1}\) 必然在 \(m_{2}\) 之前被传递。
-
FIFO-total order broadcast
是 FIFO broadcast 和 Total order broadcast 的结合
Relationships between broadcast models
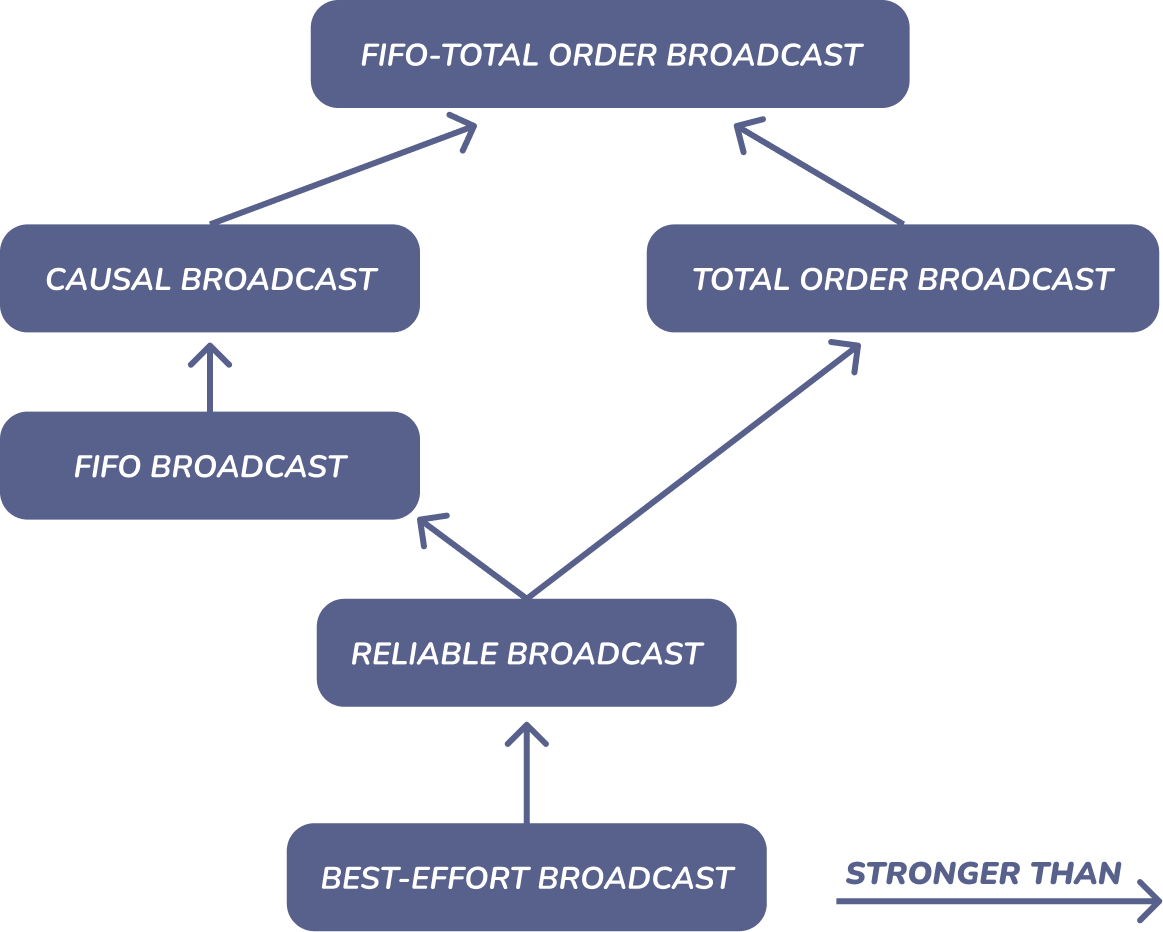
Figure 3: broadcast-models-relationship
FIFO-total order broadcast 是一个严格意义上比因果广播更强的模型;换句话说,每个有效的 FIFO-total order broadcast 协议也是一个有效的 causal broadcast 协议(反过来就不是了),其他协议也是如此。
Broadcast algorithms
实现广播算法,简单来说,涉及到两个步骤。
- 确保每个节点都能收到每天消息
- 以正确的顺序传递这些消息
首先研究如何可靠地传递消息,当一个节点想要广播一条消息时,它就单独向其他每个节点发送消息,使用上面提到过的 reliable links。但很可能一条消息丢失,发送的节点在重新发送前就崩溃了,这种情况下,丢失的这条消息对应的节点就无法接收到这条消息。
为了提高可靠性,可以让其他节点帮忙。例如,当一个节点第一次收到一个特定消息时,它就把消息转发给其他每个节点(这种被称为急性可靠广播(Eager reliable broadcast))。这种算法确保了即使一些节点崩溃,所有剩下的非故障的节点都会收到每条消息。然而,这种算法很低效:在没有故障的情况下,每条消息在由 \(n\) 个节点组成的小组中要发送 \(O(n^{2})\) 次,每个节点要收到每条消息 \(n-1\) 次,意味着占用了大量的带宽。
eager reliable broadcast 的变体沿着不同维度(比如容错性、所有节点接收消息的时间和被使用的带宽)优化,其中最常见的是流言协议(Gossip protocols,也被叫做流行病协议(Epidemic protocols))。在这些协议中,一个想广播消息的节点将其发送给随机选择的少量固定数量的节点。第一次收到信息时,一个节点会将其转发给固定数量的随机选择的节点。这类似于流言、谣言或传染病在人群中的传播方式。
Gossip protocols 并不能保证所有节点都能收到消息:在随机选择节点时,有可能总是遗漏了一些节点。然而,如果算法的参数选择得当,信息不被传递的概率很小。Gossip protocols 很有吸引力,在正确的参数下,对消息丢失和节点崩溃有很强的弹性,同时还能保持高效。其实核裂变的发生过程,也类似于这种协议。
可以在 eager reliable broadcast 或 gossip protocol 的基础上,建立 FIFO、causal 或者 total order broadcast。
Replication
现在要讨论的是复制的问题,也就是在多个节点上维护相同数据的复制体,每个节点被称为副本。复制是许多分布式数据库、文件系统和其他存储系统的一个标准特征。它是我们实现容错的主要机制之一:如果一个副本出现故障,我们可以继续访问其他副本上的数据副本。2
- 在不同节点维护相同数据的副本
- 数据库、文件系统、缓存等等
- 维护相同数据的节点叫做副本
- 如果一些副本出错,其他副本依旧是可访问的。
- 将负载分散到多个副本
- 如果数据没有变化,维护很简单,只需要复制。
- 专注于数据变化
相较于 RAID (Redundant Array of Independent Disks):在单个计算机内复制。
- RAID 只有一个控制器;在分布式系统中,每个节点都是独立的。
- 副本可以在全世界靠近用户的地方分布(CDN 本质其实是一种大规模分布式多级缓存系统)
Manipulating remote state
在更新不同节点数据时,丢失数据或者丢失 TCP 返回的 \(ACK\)3 时,就会使得不同节点之间的副本不一致,不满足幂等性(Idempotent)。为了解决这个问题,可以给每次更新操作都加上一个逻辑时间戳,并将其作为数据存储在数据库当中;当需要删除这条记录时,实际上并没有删除,而是写入一个特殊的值(称为墓碑 tombstone),将其标记为删除。(其实就类似于软删除)

Figure 4: reconciling-replicas
在许多副本系统中,副本运行一个协议来检测和调和任何差异(这被称为反熵 anti-entropy),以便副本最终持有相同数据的一致副本。由于有了 tombstone,反熵过程可以分辨出已经被删除的记录和尚未被创建的记录之间的差异。由于有了逻辑时间戳,可以分辨出一条记录的哪个版本比较老,哪个版本比较新。然后,反熵过程会保留较新的记录并丢弃较旧的记录。
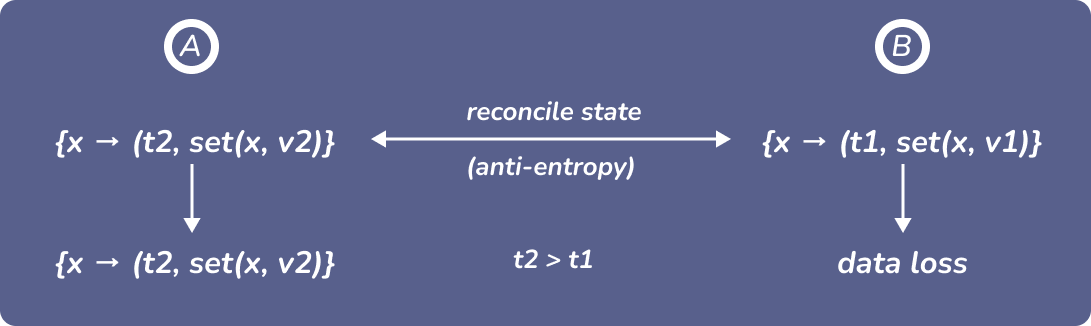
Figure 5: concurrent-reconciling-replicas
如果同时两个请求分别想把两个副本的 \(x\) 的值进行修改。
-
Last writer wins (LWW):
采用 Lamport clocks 时,$t2 > t1$则保留 \(v_{2}\) 丢弃 \(v_{1}\)。
-
Multi-value register:
采用 Vector clocks 时,\(t_{2 } > t_{1}\) 则保留 \(v_{2}\) 丢弃 \(v_{1}\); \(t_{2} \rVert t_{1}\) 则 \(\{v_{1}, v_{2}\}\) 都保留。
向量时钟的缺点是它们会变得很昂贵:每个客户端都需要在向量中输入一个条目,在有大量客户端的系统中(或者客户端每次重启都会有新的身份),这些向量会变得很大,可能会比数据本身占用更多内存。更多类型的逻辑时钟,如点状版本向量(Dotted version vectors)4,已经被开发出来以优化这种类型的系统。
Quorums
具体如何进行复制的细节对系统的可靠性有很大影响。如果没有容错,拥有多个副本会使可靠性变差:副本越多,任何一个副本在任何时候出现故障的概率就越大(假设故障不是完全相关的)。然而,如果系统在一些有问题的复制体中仍然继续工作,那么可靠性就会提高:所有副本在同一时间出现问题的概率要比一个副本出现问题的概率低很多。
Read-after-write consistency
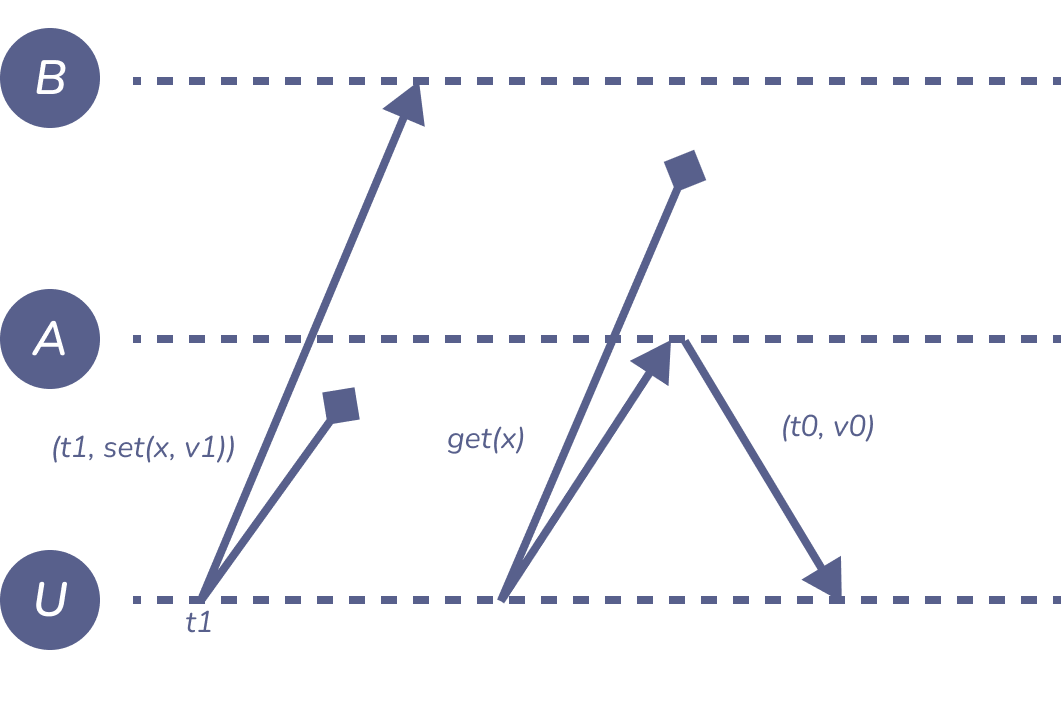
Figure 6: read-after-write-consistency
一个副本写入了数据,从另外一个副本读取,用户并没有读取到他刚刚提交的内容。如果要保持读写一致性(read-after-write consistency),则要两个节点都同时写入和读取,一旦有一个不可访问就会破坏读写一致性,没有任何容错率可言。
Quorum (2 out of 3)
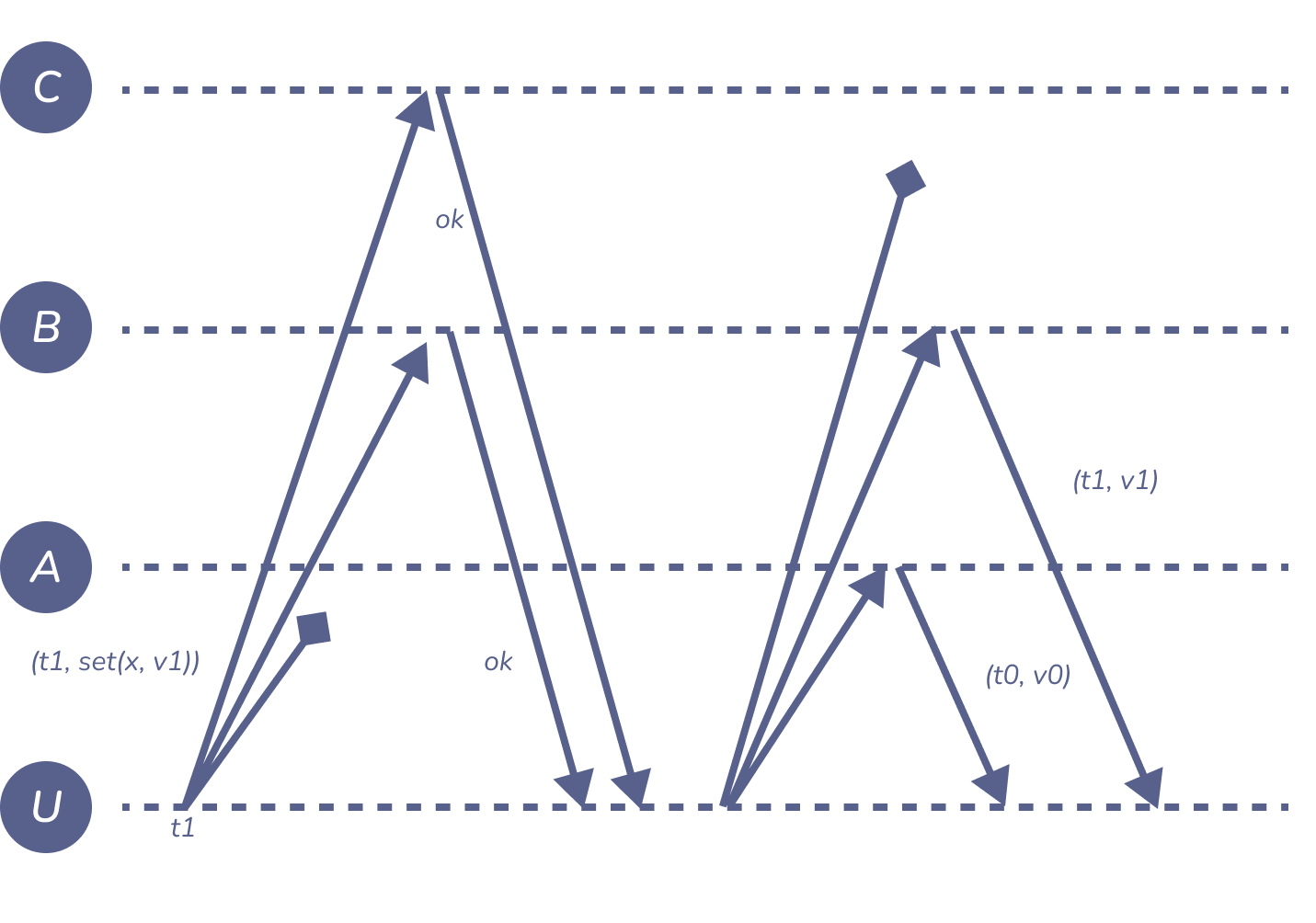
Figure 7: quorum
通过使用三个副本可以解决这个难题5。将每个读写请求发送到所有三个副本,但只要收到 \(\geq2\) 个响应,就认为请求成功。在这个例子中,写在复制体 \(B\) 和 \(C\) 上成功,而读在副本 \(A\) 和 \(B\) 上成功。对读和写都采用 “三选二 “的策略,可以保证至少有一个对读的响应来自看到最近写的副本(在这个例子中,这是副本 \(B\))。
对于同一个请求,不同的副本可能会返回不同的响应:在上图中,\(A\) 处读取会返回初始值 \((t_{0}, v_{0})\),而 \(B\) 处的读取会返回该客户端之前写入的 \((t_{1}, v_{1})\)。利用时间戳,客户端可以知道哪个响应是最近的,将 \(v_{1}\) 返回给 Application。
在这个例子中,响应写请求的副本集合 \((B, C)\) 是一个 write quorum,而响应读请求的集合 \((A, B)\) 是一个 read quorum。一般来说,quorum 是一个最小的节点集合,它必须对某个请求作出响应才能成功。为了确保读写一致性,write quorum 和 read quorum 必须有一个非空的交集:换句话说,read quorum 必须包含至少一个已经被承认的 write quorum。
在分布式系统中,常见的 majority quorum 是由超过半数的节点组成的任意子集。在三个节点的系统 \(\{A, B, C\}\) 中,majority quorum 可以是 \(\{A, B\}\)、\(\{A, C\}\) 和 \(\{B, C\}\)。通常来讲,奇数节点的系统,\(\frac{n+1}{2}\) 大小的任意子集就是 majority quorum,偶数节点的系统,需要四舍五入 \(\left \lceil \frac{n+1}{2} \right \rceil = \frac{n+2}{2}\)6。majority quorum 有个特性:任意两个 quorums 至少有一个共同的元素,也就是交集至少有一个节点。
只要不超过 \(n-w\) 个副本不可用(\(w\) 是 write quorum 的数量),系统就可以正常的处理更新;同样的,只要不超过 \(n-r\) 个副本不可以(\(r\) 是 read quorum 的数量),系统就可以正常的处理读请求。对于 majority quorum 来说,三个副本的系统可以容错一个节点,五个副本的系统可以容错两个节点,以此类推。
在这种基于 quorum 的方法下,一些副本会错过一些更新。上图中,副本 \(A\) 错过了 \((t_{1}, v_{1})\)。让副本互相同步使其数据一致的方法上面提到过,叫做反熵(anti-entropy)。
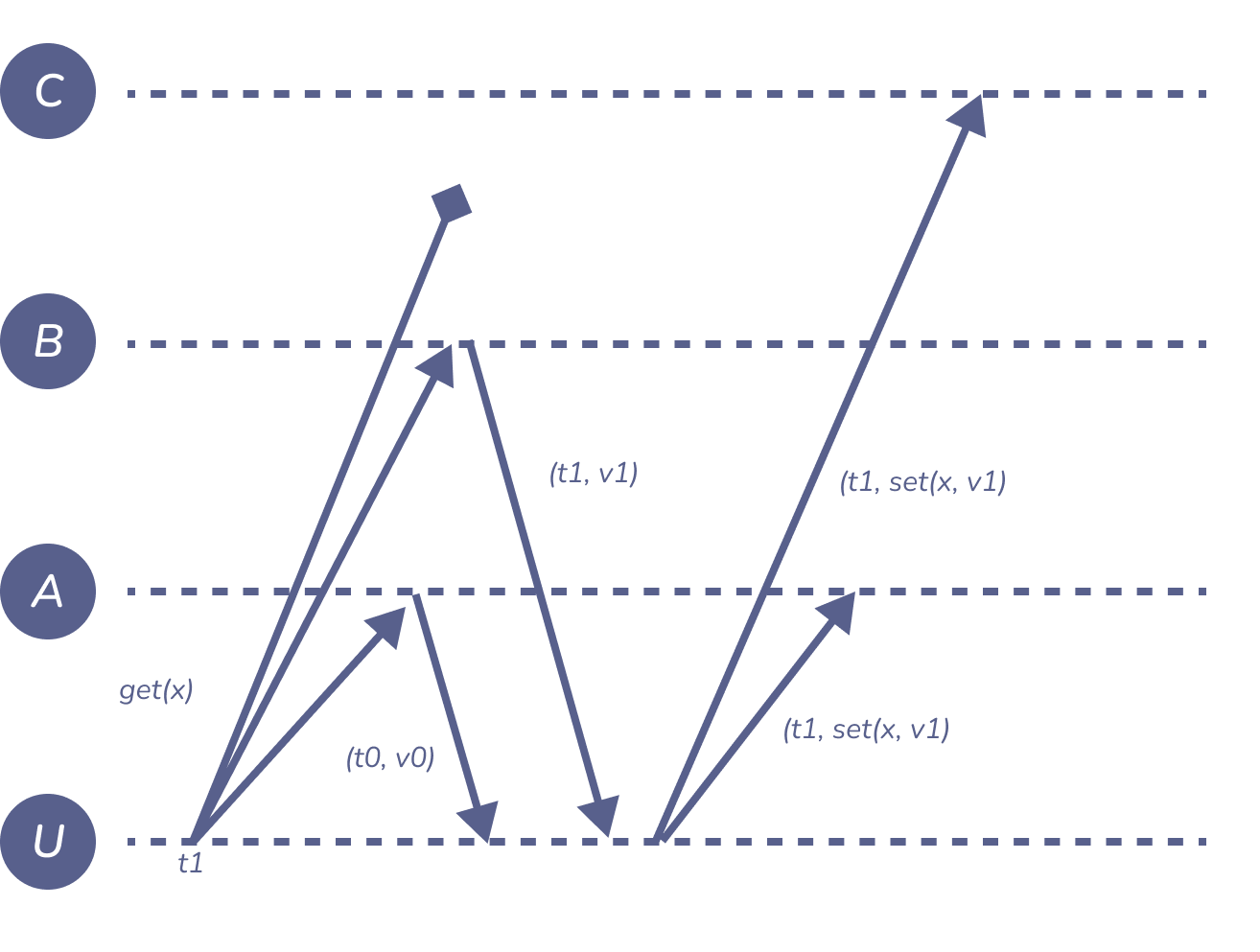
Figure 8: read-repair
另外一个方法是让客户端帮助完成传播更新的过程。例如上图中,客户端从 \(B\) 读取了 \((t_{1}, v_{1})\),但从 \(A\) 接收到的是 \((t_{0}, v_{0})\),而 \(C\) 没有回应。这个时候客户端使用原始的时间戳 \(t_{1}\) 将最新的值发送给 \(A\) 和 \(C\),\(C\) 如果已经更新了,也不过只是浪费一点点带宽。这种复制模式的数据库通常称为 Dynamo-style。
Replication using broadcast
在 quorum 中,基本上使用了 best-effort 以及客户端辅助使其他副本数据一致的方法,但这些都是不可靠的,中途会发生丢失,并且排序无法保证。
State machine replication (SMR)
FIFO-total order broadcast: 每个节点以相同的顺序传递相同的消息。
- FIFO-total order broadcast 将每次更新,更新到所有副本。
- 副本通过传递的消息来确认自身状态
- 更新具有确定性
- 副本是一种状态机:开始于固定的初始状态,以相同的顺序经历相同序列状态的变换 \(\Longrightarrow\) 所有副本都以相同的状态结尾
利用 FIFO-total order broadcast 很容易建立一个复制系统:将每个更新请求广播给副本,副本基于传递的每个消息更新其状态。副本作为一个状态机,其输入是消息的传递,这种就叫做 state machine replication (SMR)。只要更新逻辑是确定的:任何两个处于相同状态的复制体,被赋予相同的输入,最终必须处于相同的下一个状态。甚至错误也必须是确定的:如果一个副本的更新成功了,但在另一个副本上失败了,它们就会变得不一致。
SMR 的一个优秀特点是,从一个状态到下一个状态只要是确定的,其中的逻辑可以任意复杂。例如,可以处理具有任意业务逻辑的整个数据库事务,而这个逻辑可以同时依赖于广播信息和数据库的当前状态。一些分布式数据库以每个副本独立执行相同的确定性交易代码(这被称为主动复制)来实现复制。这一原则也是区块链、加密货币和分布式账本的基础:区块链中的 “区块链 “无非是由 Total order broadcast 传递的消息序列,每个副本都确定性地执行这些区块中描述的交易,以确定账本的状态(例如,谁拥有哪些钱)。一个 “智能合约 “只是一个确定的程序,当一个特定的消息被传递时,副本会执行这个程序。

密切相关的概念:
- 可序列化事务(按传递顺序执行)
- 区块链、分布式账本、智能合约。
限制:
- 不能立即更新状态,必须等待广播传递。
- 需要容错的 total order broadcast
State machine replication 的缺点是 total order broadcast 的限制。当一个节点想通过 total order broadcast 来广播一个消息时,它不能立即将该消息传递给自己。之前讲过,传递给自己的消息也要遵从总秩序,所以当使用状态机复制时,想要更新其状态的副本要等待广播,与其他节点协调,并等待更新信息被传递给自己。状态机复制的容错性取决于底层 total order broadcast 的容错性。尽管如此,基于 total order replication 的复制还是被广泛使用。
在 Total order broadcast 中提到过一种实现方法是指定一个节点作为 Leader,并将所有的消息通过它来路由,保证传递的顺序。这一原则也被广泛应用于数据库副本:许多数据库系统指定一个副本作为 leader,primary 或者 master。所有修改数据库的事务都需要在 leader 副本上执行。虽然 leader 会同时执行多个事务,但事务提交时会按照总的顺序提交。当事务提交后, leader 副本将数据变动广播给所有的 follow 副本,follow 副本按照之前提交的顺序在本地进行事务提交,这种方法被称为被动复制(passive replication)或者主从复制(primary-backup replication),这样的方式其实和 Total order broadcast 是等效的。
至于之前提到的其他广播方式,也可以用作复制,但需要更加小心,保证副本之间数据的一致性。
The Raft consensus algorithm
为了实现容错的 FIFO-total order broadcast,Raft 的具体实现细节可以参见 Raft consensus algorithm,另外有个非常好的动画示意网站可以更加直观的观察整个过程。。
集群内的节点都对选举出的领袖采取信任,因此 Raft 不是一种拜占庭容错算法。
Replica consistency
事务的关键是原子性。当一个事务跨越多个节点时,希望整个事务仍然具有原子性:也就是说,要么所有节点都必须提交事务且具有持久性,要么所有节点都回滚。因此,各节点之间就事务应该终止回滚还是提交要达成一致。这里说的一致和 Raft 中的不太一样,细节上有很大不同。
| Consensus | Atomic commit |
|---|---|
| 一个或多个节点提出一个值 | 每个节点投票是否提交或中止 |
| 任意一个提出的值都可以被承认 | 如果所有的节点投票提交那么就必须提交;如果所有的节点都投票中止那么就必须中止。 |
| 只要 quorum 数量的节点可以工作,崩溃的节点是可以被容忍的。 | 如果不分的节点崩溃,必须中止。 |
用来保证多个节点 atomic commitment 最常用的算法是 two-phase commit protocol (2PC),也有 three-phase commit protocol,但这里不做研究。
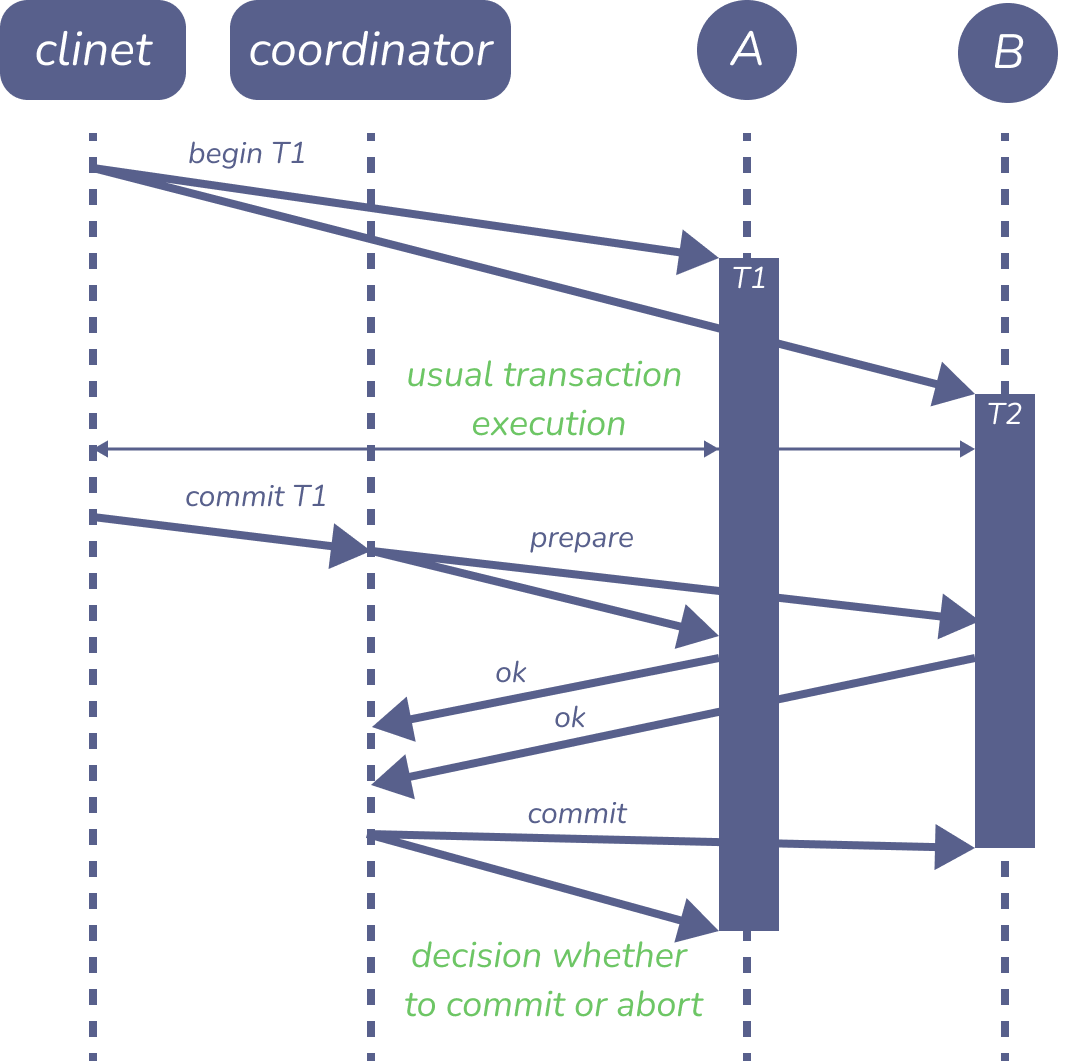
Figure 9: Two-phase commit (2PC)
当使用 two-phase 提交时,客户端首先在参与交易的每个副本上启动一个常规的单节点交易,并在这些交易中执行常规的读写操作。当客户端准备好提交交易时,它向交易协调者(一个管理 2PC 协议的指定节点)发送提交请求。(在一些系统中,协调器是客户端的一部分)。
协调器首先向参与交易的每个副本发送一个准备消息,每个副本都会回复一个消息,表明它是否能够提交交易(这是协议的第一阶段)。副本实际上还没有提交交易,但它们必须确保在第二阶段中,当协调者发出指示,它们一定能够提交交易。这就意味着,副本必须将交易的所有内容更新写入磁盘,并在回复准备信息之前检查完整性约束,同时继续持有交易的任何锁。
协调器收集响应,并决定是否实际提交交易。如果所有节点都回复 OK,协调者就决定提交;如果任何节点想放弃,或者任何节点未能在某个超时时间内回复,协调者就决定放弃。然后,协调者将其决定发送给每个副本,它们都按照指示提交或放弃(这是第二阶段)。如果决定是提交,每个副本保证能够提交其事务,因为之前的准备请求奠定了基础。如果决定放弃,副本就会回滚该事务。
Reference
- Cachin, Guerraoui, Rodrigues (2011) Introduction to Reliable and Secure Distributed Programming (2. Ed.)., Springer.